

Professor Mohsen Bayati is using complex mathematical models to better predict who is likely to be rehospitalized within a month of discharge. (Associated Press photo by David Goldman)
When your doctor sends you to the lab for tests, the two of you hope to get back clues to your most important health issues. In the near future, there may be computers analyzing those test results in a new way — along with prescriptions, doctors’ visit notes, and other electronic medical records — to better predict your health risks and customize your treatment. Working to develop accurate methods for this kind of big-data science is Mohsen Bayati of Stanford Graduate School of Business. A mathematician and engineer by training, he works with those trained in medicine to design and test algorithms for analyzing digitized medical data.
With enough records and carefully constructed algorithms, Bayati and others believe that we can have better health for the money spent on health care. That’s because computers can harvest more knowledge about risk from electronic health records than humans alone can, and they can discover correlations more quickly than can be done now through controlled clinical studies. As aides to doctors and other medical professionals, these data analysis systems are expected to lead to more efficient, yet more customized, health care.
Using complex mathematical models, so far Bayati has learned that it is possible to improve the treatment of senior citizens hospitalized with congestive heart failure by better predicting who is likely to be rehospitalized within a month of discharge. In a study partially funded by Microsoft Research and the National Science Foundation, he was part of a team that looked for cost-effective ways to reduce the 30-day hospital readmission rate, which has been about 20% for this group of patients and costs about $14,000 for each readmission.
“We found that we can rank patients according to risk much more accurately than before by applying machine learning on digital data,” he says of the 2009-2011 study at a large urban hospital in the U.S. “That means we can get quality improvements at less cost.”
The idea, he says, is to move from “fee-for-service medicine to pay for performance. If you want to make pay for performance possible, the concept of assessing and adjusting risk becomes important, meaning the hospital needs to tell accurately which patient has a higher risk than other patients.” Indeed, if only 20% of congestive heart failure patients need to be readmitted in a month, then providing such extra services to 100% of people with the condition is not cost-effective quality improvement and contributes to high medical bills for all.
Programs for reducing readmissions are not new, but they are more likely to be emphasized now that the Affordable Care Act promises hospitals financial incentives for reducing their readmission rates. Some hospitals have been able to reduce readmissions by having nurse teams provide more counseling at the time of discharge or by hiring medical professionals to visit discharged patients in their homes or phone them for follow-ups.
Other hospitals have learned to be more effective by developing a risk score from a small number of variables about the health status of patients. Patients with the highest risk scores then get added services to bring down their risk.
With machine analysis of patient records, thousands of variables can be used to calculate a patient’s relative risk of being readmitted. Furthermore, the risk can be updated automatically every few minutes, based on any new test results or observations entered into the patient’s record by a health care professional.
In a summary of their congestive heart failure research, Bayati and colleagues said: “Improvements in the accuracy of classifiers lead to greater selectivity in the application of programs and greater overall benefits to hospitals and patients.” For example, by using the patient-specific decision analysis, in one case involving a treatment that cost about $1,300 but was effective only in about a third of patients, they were able to both reduce hospitalizations and save overall costs.
This particular research has been used by Caradigm, a joint venture by Microsoft and General Electric, in risk assessment software for hospitals. Other technology companies are also beginning to offer medical risk assessment software or services, but their methodologies differ and generally are not public, Bayati says. “I am continuing to research how we can do better.”
Generating accurate risk assessments involves such complexities as accurately knowing the time lag between, say, a diagnosis of diabetes and starting drug A or the patient complaining to a doctor of a cardiovascular problem. Such sequential analysis of health-related events adds layers of complexity.
But even after coming up with a risk assessment based on these medical events, the job is not over.
“If you tell me the risk, then I want to know what I should do to lower it,” Bayati says. That means a second research step with a new group of patients to make sure the recommendations suggested actually work to reduce various types of readmission. Another example is using electronic records to predict who is most at risk of acquiring an infection while hospitalized.
It’s important to recognize that real-time decision analysis systems for guiding doctors would not yield net savings, he says, for interventions that are inexpensive and effective for large proportions of patients. In that case, the greatest efficacy and quality is achieved by giving the treatment to everyone identified with the diagnosis. Nor would it be effective for very expensive treatments that help only a few people who cannot be identified in advance of the treatment. In the heart failure population studied, however, the researchers found that for treatments with intermediate to higher costs and efficacies, a relative savings of nearly 10% could be achieved.
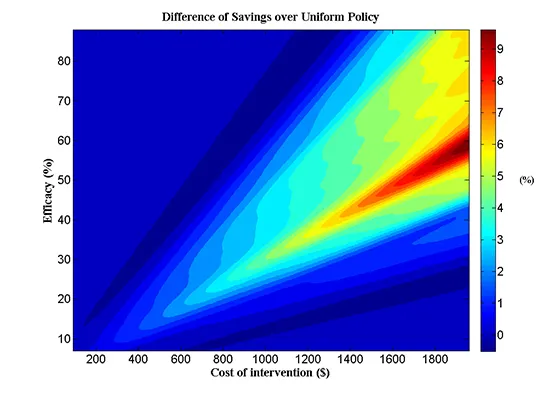
When electronic records can be used to find which patients would benefit from a particular treatment, the overall cost of health care can go down while the quality goes up. The percent of patients who will be helped by a given treatment is related to the cost of the treatment in this chart. The hotter colors show the range where savings can be achieved by implementing a selective treatment policy that is guided by computerized predictions versus a uniform implementation of the treatment. (Graphic by Mohsen Bayati)
There are potential pitfalls, however, with correlations. Algorithms looking for relationships in data can be expected to find some relationships that aren’t likely to be what they seem, Bayati says, and if not used judiciously, the results could lead to arbitrary discrimination against some patients, treatments, or health care organizations. “For example, in one of our studies on predicting general readmissions to the hospital, we discovered that ‘cocaine test: negative’ raises the likelihood that a patient will be readmitted. A subsequent inquiry revealed that clinicians usually only administer a cocaine screening if they had suspicions that a patient may be a drug abuser.” Obviously then, avoiding cocaine should not be assumed to worsen your health.
Such examples help explain why human decisions will remain a critical component of health care for the foreseeable future, Bayati says, but they also point to the promise of teasing apart complexities that the best doctors and expensive clinical trials have not been able to find due to the smaller sample sizes of their experience.
Take, for example, antiplatelet therapy, which has proved to be very effective at reducing the risks of blood clots among patients who have had heart attacks. Yet, in a subgroup of diabetic patients, Bayati points out, the therapy actually increases the risk. Clinical trials are not large enough to find such effects but they can be found in large data sets. That is why the U.S. Food and Drug Administration hopes to use electronic medical records to find interactions between various diseases with drugs and various drugs with each other that were not possible to find in the trials conducted before a new drug is on the market.
This is an exciting time, Bayati says, to apply his background in building complex mathematical models to medicine. “We do think we can improve quality and also lower cost.”
For media inquiries, visit the Newsroom.





